StopWords and Lexicon Normalization for Sentiment Analysis
Sentiment analysis aids in understanding human behavior for national security, political campaigns, and scientific research. It also allows businesses to gain valuable marketing information from customer reviews, social media sites, online blogs, and various internet forums. Not surprisingly, sentiment analysis is a very common yet crucial natural language processing (NLP) task that many data scientists are required to perform.
We will use TextBlob and VADER perform sentiment analysis on Yelp restaurant reviews in the D.C. Metro Area. The goals of this blog are to compare the sentiment polarity scores using both libraries with the actual Yelp food review ratings and to understand why removing StopWords and Lemmatization are not always necessary for text analytics.

Before diving into the analysis, we will quickly go over the Yelp review data set and gain a bit more understanding on the polarity scores for both libraries. Our data set consists of 12,642 food reviews for the Washington, D.C. area collected from the Yelp Reviews API. Limitations with this data set are that endpoint only returns the first three reviews using Yelp’s default sort order and only the first sentence of each review is returned.
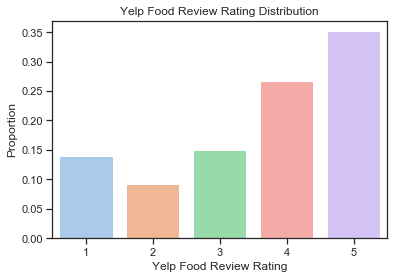
As you can see from the bar chart below, the data contains more positive reviews (rating > 3) than negative ones (rating < 3). Both the higher distribution of the positive reviews and the text excerpts can impact the polarity score prediction results.
The polarity scores for both TextBlob and VADER are scaled from -1 to 1. A score of higher than 0.5 is positive, between -0.5 to 0.5 is neutral, and below -0.5 is negative.
Typically there are two ways to perform sentiment analysis:
- Lexicon Pattern based: Use a dictionary of predefined patterns to count the occurrences of positive and negative words in a given paragraph.
- Machine learning based: Build a classification model.
We focus mostly on the first approach to compare the results. You can find the detailed PolarityScore class code for obtaining sentiment scores using both TextBlob and VADER here.
This class also returns positive and negative review classification results using TextBlob’s NaiveBayesAnalyzer function.
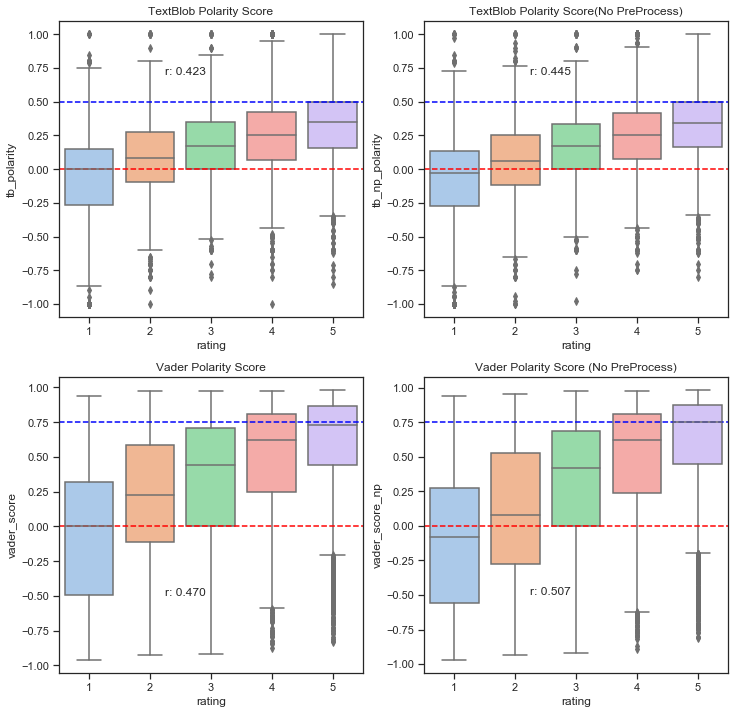
The box plots above compared the TextBlob and VADER polarity score results with and without removing StopWords and Lemmatization for the 12,642 Yelp Review data points. The r’s in the plots represent the correlation coefficient between the actual Yelp review ratings and the polarity scores. Based upon the r values alone, we can conclude that VADER sentiment analysis with zero text preprocessing appears to perform the best. The VADER sentiment polarity compound scores slightly outperformed the TextBlob pattern analyzer polarity scores. This could be because VADER tends to take punctuation such as “!” , capitalization, ex. “GREAT” vs. “great”, preceding trigrams, and StopWords such as “but” into consideration as well as the fact that TextBlob doesn’t punish negation. One interesting thing to note is that both libraries tend to perform quite poorly for negative scores (Yelp reviews < 3). Moreover, removing StopWords and Lemmatization actually made identifying negative reviews more difficult. Intuitively, it actually makes perfect sense. StopWords such as “not”, “very”, and “but” can be quite helpful when it comes to identifying negative emotions. Words with the same base roots such as “worse” and “bad” or “better” and “good” exhibit different emotional intensities but will be ignored after Lemmatization. For these reasons, it is not always a great idea to remove StopWords or perform Lemmatization for sentiment analysis. The limitations of the dataset as mentioned earlier could also be negatively impacting the polarity score prediction results.
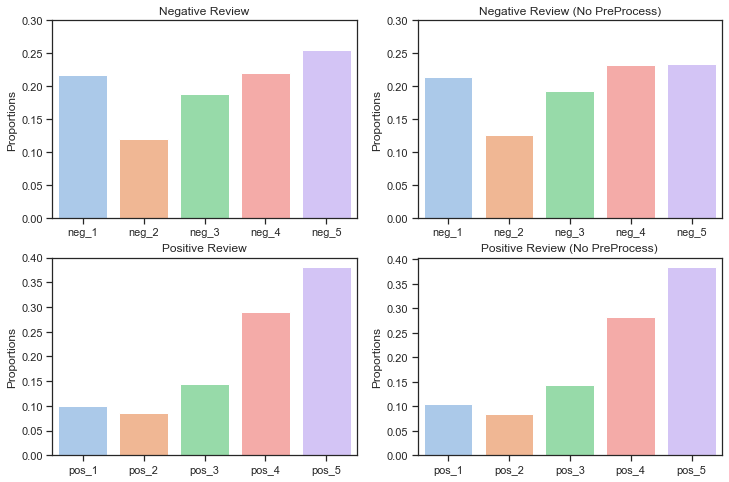
Finally, TextBlob’s NaiveBayesAnalyzer function is used to classify 1,736 randomly selected reviews into positive and negative categories. The bar plots shown below compare the classification results using both preprocessed and raw reviews. Just like the VADER and TextBlob lexicon based predictions, The NaiveBayesAnalyzer also appears to perform much worse for negative reviews. Another interesting observation is that the PreProcessing for the Bayes classifier method actually yielded slightly better result than No PreProcessing reviews for the negative reviews while the No PreProcessing performed slightly better for the positive reviews. It appears that the StopWords such as “not” or “but” are not as useful for the Bayes classifier as the VADER and TextBlob pattern analyzers. For Bayes classifier, further feature engineering such as bigram or trigram can better improve context clues.
In summary, we used VADER and TextBlob to predict DC Yelp Food Review sentiments. VADER tends to outperform TextBlob due to its better consideration of context and the fact that TextBlob doesn’t punish negation very well. The final key takeaway is that removing StopWords and Lemmatization are often times not just unnecessary but can be harmful for pattern based sentiment analysis.
{kind=link}