A Practical Guide for LLM Customization: Mastering Prompt Engineering
In our first post, we outlined the three core techniques for LLM customization. Today, we’re diving deep into the most accessible approach: Prompt Engineering. This isn’t just about “asking better questions”—it’s about becoming a systematic cognitive architect who can deliberately shape model behavior through carefully crafted instructions.
This guide covers six essential steps: understanding your models, designing conversations, controlling generation parameters, mastering core techniques, building intelligent agents, and implementing production-ready prompt management.
Step 1: Know Your Model Foundation
Your prompting strategy depends entirely on which type of model you’re working with:
Base LLMs: Raw foundational models trained purely on next-word prediction. They’re creative and flexible but don’t reliably follow instructions. Think of them as a “blank canvas” primarily useful for fine-tuning projects.
Instruction-Tuned LLMs: Base models enhanced through supervised fine-tuning and reinforcement learning from human feedback (RLHF) to follow instructions (GPT-4, Claude, Gemini). These have a built-in “helpful assistant” persona that introduces what prompt engineers call the alignment trade-off—you gain consistency and safety but may need to work around embedded behaviors.
Key Insight: Nearly all prompt engineering work uses instruction-tuned models, so understanding their behavioral patterns is crucial for effective prompting.
Step 2: Architect the Conversation Structure
Modern LLMs are trained to interpret structured conversation roles. Let’s use a consistent example throughout: summarizing research papers in a friendly yet professional style.
System Messages: Provide global, persistent instructions that define the model’s role and behavior:
You are an expert at summarizing academic research papers.
Write in a friendly, professional tone, highlighting key findings
and contributions in ≤200 words. Focus on practical implications
and methodological innovations.
User Messages: Contain the specific task or query:
Summarize the following paper's main contributions and findings:
[Paper content or abstract]
Implementation Note: Different providers use varying syntax ({"role": "system"} in APIs, special tokens in chat interfaces), but the conceptual framework remains universal.
Step 3: Control Generation Parameters
Prompt content is only half the equation—generation parameters shape output style and reliability:
Temperature (0.0-2.0): Controls randomness
- Low (≤0.3): Precise, factual, deterministic
- High (≥0.8): Creative, varied, exploratory
Top-p/Nucleus Sampling (0.0-1.0): Selects from top fraction of probable tokens
- Low values (0.1): Precise, focused on most likely tokens
- High values (0.9): Creative, allows diverse token selection
- Typically tune either temperature OR top-p, not both
Presence Penalty: Discourages token reuse, encouraging novelty Frequency Penalty: Prevents repetitive token patterns
Max Output Tokens: Critical for cost control and response structure
- Warning: Setting too low truncates responses mid-sentence
- Best Practice: Set 20-30% higher than expected output length
Step 4: Core Prompting Techniques
These techniques can be applied in user prompts (task-specific) or system prompts (persistent behavior):
Zero-Shot Prompting
Direct instruction without examples. Best for simple, well-defined tasks.
Example: "Translate 'I would like a coffee' into French."
- Pros: Fast, cost-effective, minimal context usage
- Cons: Lower reliability for complex or nuanced tasks
Few-Shot Prompting
Provide 2-5 examples to establish patterns and formatting expectations.
Example:
Text: "The food was terrible." → Sentiment: Negative
Text: "I had a great time." → Sentiment: Positive
Text: "The service was slow." → Sentiment: [Model completes]
- Pros: Excellent for formatting consistency and capturing nuance
- Cons: Higher token costs, potential “lost in the middle” effects
Chain of Thought (CoT)
Guide the model through step-by-step reasoning processes (original research paper).
Example: "A farmer has 15 apples, sells 7, then splits the rest into 4 baskets. How many per basket? Let's think step by step."
- Pros: Dramatically improves logical reasoning and complex problem-solving
- Cons: Longer outputs increase costs; potential for verbose hallucinations
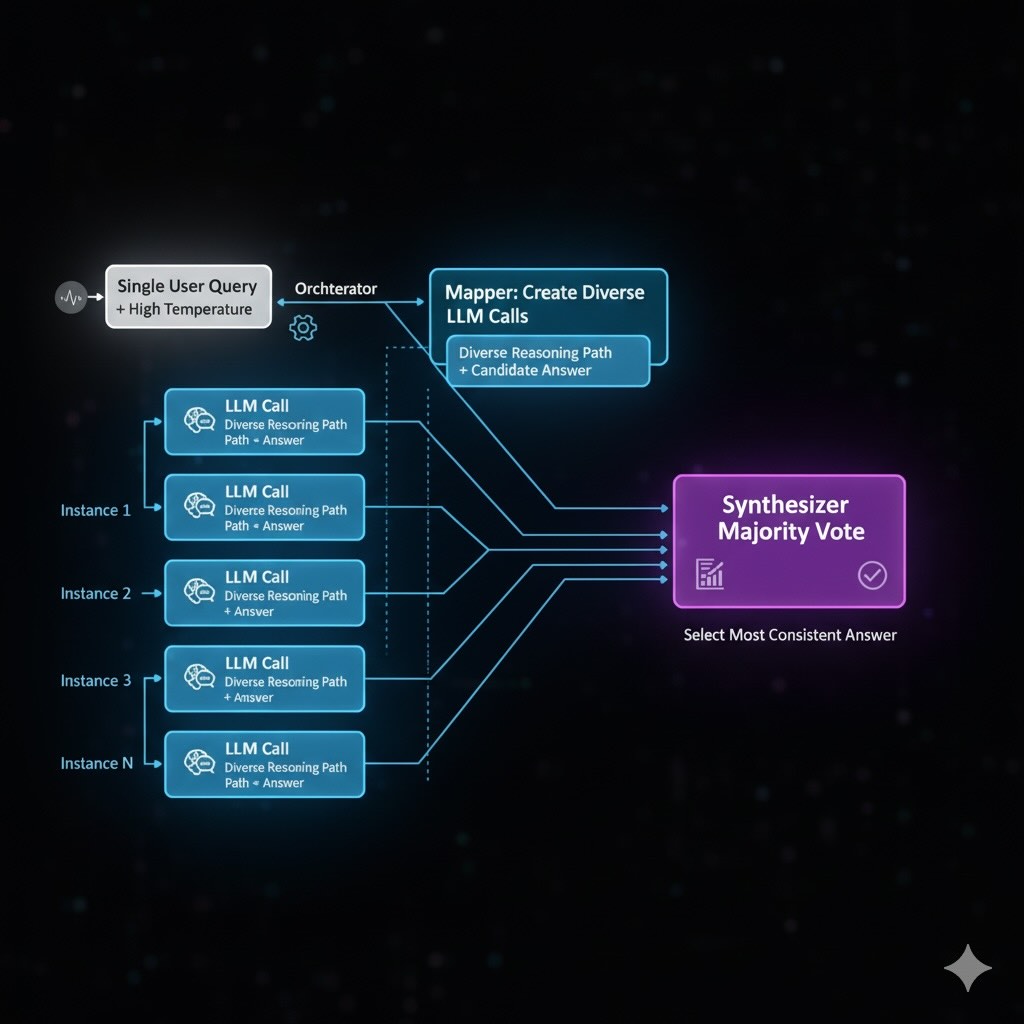
Self-Consistency
Execute CoT multiple times with higher temperature, then aggregate results through majority voting.
- Pros: State-of-the-art accuracy for reasoning tasks
- Cons: High latency and API costs
- Agentic Implementation: Use orchestrated multi-agent pattern:
- Orchestrator: Manages the overall workflow and coordinates agent communication
- Mapper: Spawns multiple parallel reasoning agents with different temperature settings
- Synthesizer: Aggregates results using majority voting or weighted confidence scoring
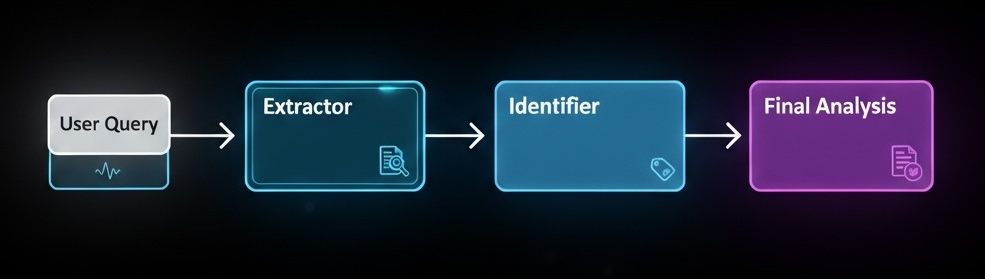
Prompt Chaining (Sequential Prompting)
Break complex tasks into a sequence of smaller, focused prompts where each step’s output becomes the next step’s input.
Example - Document Analysis Workflow:
Step 1: "Extract key themes from this research paper: [paper text]"
Step 2: "Based on these themes: [themes from step 1], identify potential applications"
Step 3: "Given these applications: [applications from step 2], assess market viability"
- Pros: Better control over reasoning flow, easier debugging, modular task design
- Cons: Multiple API calls increase latency and costs, requires output parsing between steps
- Best Use Cases: Complex analysis workflows, multi-step content generation, progressive refinement tasks
- Agentic Implementation: Can be orchestrated using specialized agents for each step (e.g., Extractor → Analyzer → Evaluator agents) with a coordinator managing the sequence and data flow
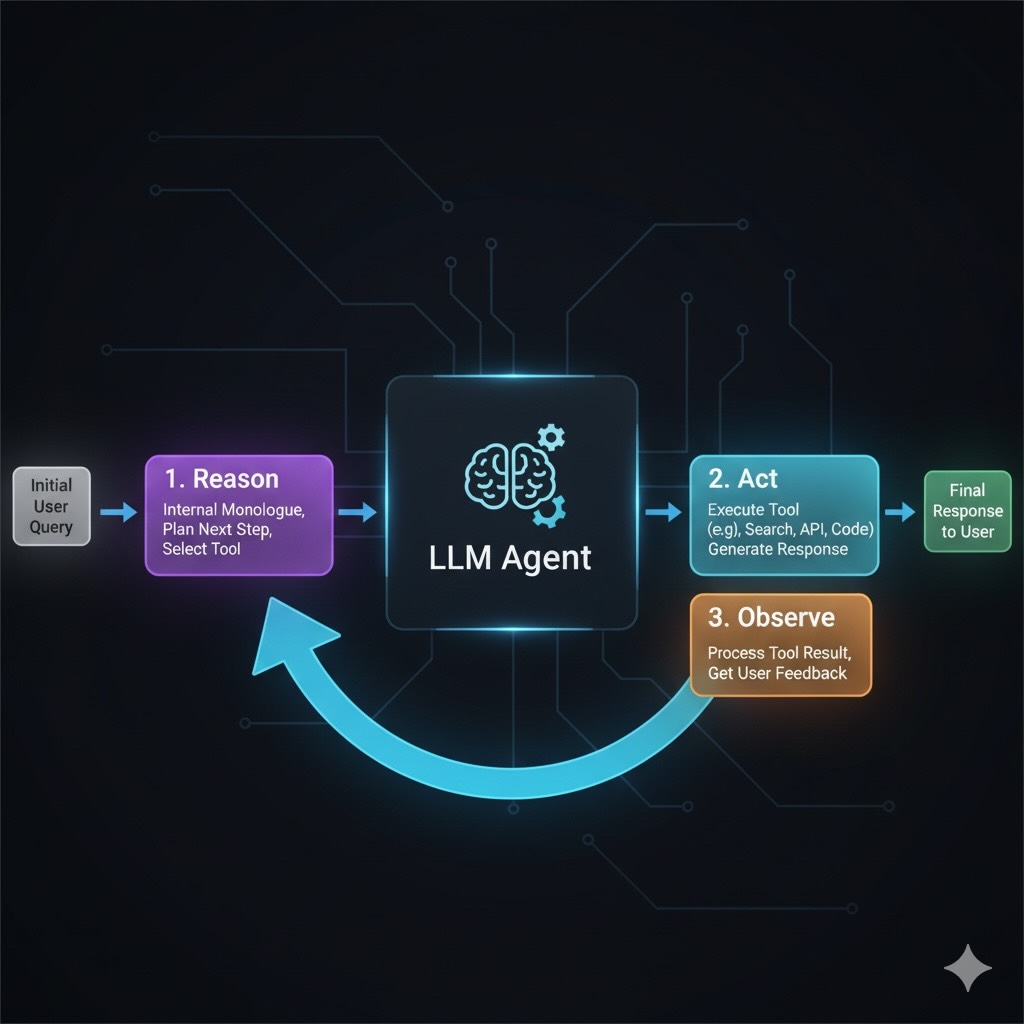
Step 5: Building Intelligent Agents with ReAct
ReAct (Reason + Act) interleaves internal reasoning with external tool calls, enabling multi-step workflows that accumulate and refine information (original research paper).
Multi-Step Research Workflow Example
User Request: "Research AI's impact on medical imaging over the past 5 years. Find key studies and synthesize findings with citations."
Agent Process:
- Reason: “Need recent studies from 2020-2025 on AI medical imaging applications”
- Act:
search("AI medical imaging review 2020-2025 deep learning") - Observe: Retrieve candidate papers (titles, abstracts, DOIs)
- Reason: “Select top 5 most relevant papers based on citation count and recency”
- Act:
extract_paper_details(paper_ids)for each selected paper - Observe: Receive structured summaries of methods, results, datasets
- Reason: “Compare findings, identify trends, note contradictions and performance metrics”
- Act:
format_citations(doi_list)to ensure proper academic formatting - Final Output: Synthesized research summary with evidence-backed conclusions
Trade-offs: Increased latency and complexity, plus security considerations for external tool access.
Step 6: Production Prompt Management
Prompt Versioning and Testing
Treat prompts like code—they need version control, testing, and systematic optimization:
Prompt Versioning Strategy:
v1.0: Initial system prompt
v1.1: Added output format specifications
v1.2: Enhanced few-shot examples
v2.0: Complete restructure for better CoT reasoning
A/B Testing Framework:
- Evaluation Metrics: Task accuracy, response quality scores, user satisfaction
- Test Sets: Curated examples covering edge cases and typical usage
- Comparison Methods: Side-by-side evaluation, automated scoring, human preference
Scalable Evaluation Metrics:
- Automated Scoring: BLEU/ROUGE for content similarity, semantic similarity via embedding cosine distance
- Task-Specific Metrics: Classification accuracy, extraction precision/recall, reasoning correctness
- Business Metrics: User engagement, task completion rates, customer satisfaction scores
- Quality Assurance: Response coherence, factual accuracy, brand voice consistency
Systematic Optimization Process:
- Baseline Establishment: Document current prompt performance
- Hypothesis Formation: Identify specific improvement areas
- Controlled Testing: Modify one element at a time
- Performance Measurement: Use consistent evaluation criteria
- Iteration Cycles: Implement improvements based on data
Production Safety and Monitoring
Input Validation and Guardrails: Implement automated systems to detect and block malicious or inappropriate prompts before they reach the model
Prompt Injection Protection:
- Sanitize user inputs before processing
- Use input validation and content filtering
- Implement role-based access controls for system prompts
- Monitor for suspicious input patterns
Quality Assurance:
- Automated response quality scoring
- Anomaly detection for output consistency
- Regular human evaluation of production outputs
- Feedback loops for continuous improvement
Context Management:
- Implement chunking strategies for long documents
- Use retrieval systems for large knowledge bases
- Monitor context window utilization
- Handle truncation gracefully with fallback strategies
Production Cost Optimization:
- Prompt Compression: Remove redundant instructions, use concise language without losing effectiveness
- Caching Strategies: Cache frequent queries and responses to reduce API calls
- Model Selection: Use smaller models for simple tasks, reserve powerful models for complex reasoning
- Batch Processing: Group similar requests to optimize throughput and reduce per-request overhead
- Smart Routing: Route requests to appropriate models based on complexity and cost requirements
Technique Comparison and Selection Guide
| Technique | Primary Use Case | Implementation Complexity | Cost Impact | Best For | Browser Testing |
|---|---|---|---|---|---|
| Zero-Shot | Simple, direct tasks | Low | Minimal | Quick prototypes, well-defined problems | ✅ Full support |
| Few-Shot | Format consistency | Medium | Moderate | Structured outputs, domain-specific tasks | ✅ Full support |
| Chain of Thought | Complex reasoning | Medium | High | Logic problems, multi-step analysis | ✅ Full support |
| Self-Consistency | Critical accuracy | High | Very High | High-stakes decisions, research synthesis | ✅ Manual execution |
| Prompt Chaining | Multi-step workflows | Medium | High | Complex analysis, progressive refinement | ✅ Manual execution |
| ReAct | Multi-step workflows | Very High | Variable | Research, fact-checking, complex workflows | ❌ Requires API/tools |
Note: Most techniques can be tested directly in LLM web interfaces (ChatGPT, Claude, etc.) without API access, making experimentation immediately accessible to all engineers.
Security Considerations and Best Practices
Input Validation: Always sanitize user inputs to prevent command injection
Access Control: Restrict system prompt modifications to authorized personnel
Rate Limiting: Implement usage controls to prevent abuse and cost overruns
Monitoring: Log and analyze prompt performance and potential security issues
Sandboxing: Run agent tools in isolated environments with limited permissions
What’s Next
Prompt engineering gives you powerful control over model behavior, but it’s limited by the knowledge already encoded in the model’s parameters. In our next post, we’ll explore Retrieval-Augmented Generation (RAG)—the architectural approach that connects LLMs to your private data sources for dynamic, up-to-date responses.
Follow along as we dive into vector databases, embedding strategies, and production RAG implementations!
{kind=link}