A Practical Guide for LLM Customization (Part 3): Building Production RAG Systems
In our previous posts, we explored the foundational techniques for LLM customization and mastered prompt engineering. Today, we’re diving into Retrieval-Augmented Generation (RAG)—the architectural approach that connects LLMs to dynamic, up-to-date information sources.
RAG transforms LLMs from closed-book systems with static knowledge into open-book systems with access to your private data repositories. This guide covers the complete RAG pipeline: from knowledge ingestion through production deployment, with practical implementation strategies and evaluation frameworks.
The RAG Imperative: Beyond Static Knowledge
Large Language Models face two fundamental limitations that RAG directly addresses:
Knowledge Cutoff Problem: Models are trained on data with specific cutoff dates, making them unable to access recent information or real-time updates.
Hallucination Risk: When asked about topics outside their training data, LLMs often generate plausible-sounding but factually incorrect responses with high confidence.
How RAG Complements Prompt Engineering: While prompt engineering defines how models should think and respond, RAG provides what they should think about. Instead of relying solely on parametric knowledge, RAG enables models to ground their responses in retrieved, verifiable information.
Example Transformation:
- Without RAG:
"What was Tesla's Q2 2024 revenue?"→ High risk of hallucination - With RAG:
"Based on the following SEC filing data: [retrieved context], what was Tesla's Q2 2024 revenue?"→ Grounded, citable response
Step 1: Knowledge Ingestion Architecture
The ingestion pipeline transforms unstructured documents into a searchable knowledge base optimized for semantic retrieval.
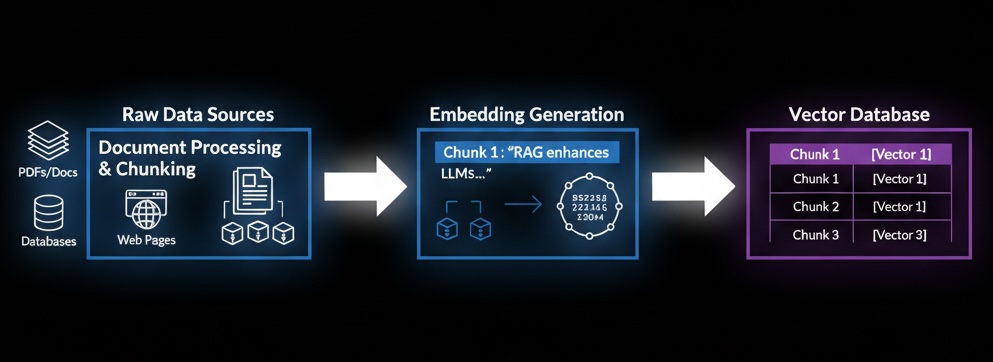
Document Processing and Chunking
Fixed-Size Chunking: Split documents into chunks of predetermined length (e.g., 512 tokens) with overlap (e.g., 50 tokens) to maintain context continuity.
- Pros: Predictable chunk sizes, simple implementation
- Cons: May break semantic units, context boundaries
Recursive Chunking: Hierarchical splitting that respects document structure (paragraphs → sentences → words).
- Pros: Preserves logical document structure
- Cons: Variable chunk sizes may complicate downstream processing
Semantic Chunking: Uses embedding similarity to create topically coherent chunks.
- Pros: Maintains semantic coherence, better retrieval relevance
- Cons: Higher computational cost, more complex implementation
Embedding Generation
Transform text chunks into high-dimensional vector representations that capture semantic meaning:
Proprietary Embedding APIs:
- OpenAI Ada-002: General-purpose, high-quality embeddings
- Cohere Embed: Strong performance on domain-specific content
- Pros: High quality, minimal setup, regular improvements
- Cons: API costs, external dependency, less control
Open-Source Embedding Models:
- Sentence-BERT variants: Domain-specific fine-tuning possible
- E5 models: Strong multilingual support
- Pros: Cost control, customization, data privacy
- Cons: Infrastructure overhead, model management complexity
Vector Database Storage
Store and index embeddings for fast similarity search using HNSW (Hierarchical Navigable Small World) algorithms, enabling sub-second retrieval across millions of vectors.
Popular Options: Pinecone (managed), Milvus (open-source), Weaviate (GraphQL), OpenSearch (Elastic integration)
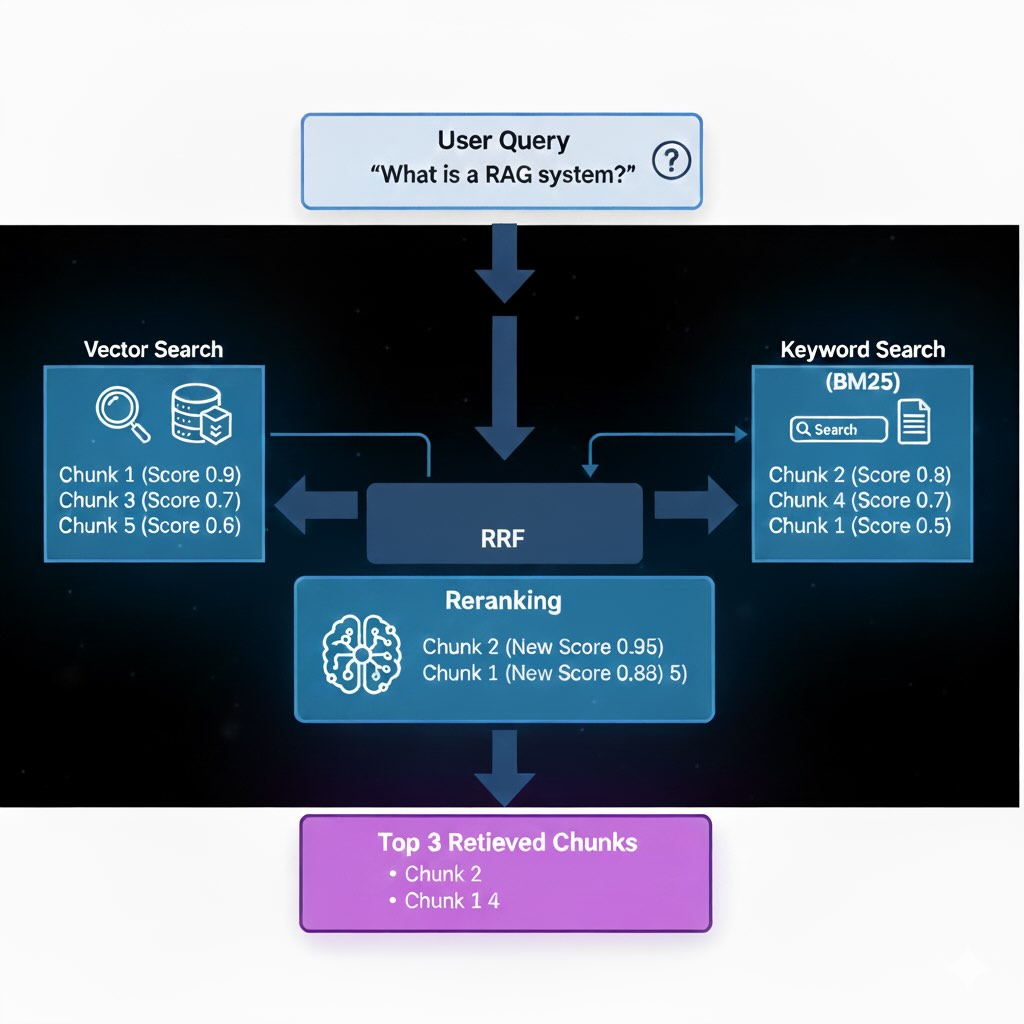
Step 2: Retrieval Pipeline Design
Effective retrieval combines multiple search strategies to maximize both recall and precision through a two-stage approach:
Stage 1: Hybrid Recall with Rank Fusion
Combine semantic vector search with traditional keyword search (BM25) using Reciprocal Rank Fusion (RRF):
\[\text{RRF Score}(d) = \sum_{i=1}^{n} \frac{1}{k + \operatorname{rank}_i(d)}\]Where k is typically 60, and we sum across vector and keyword search rankings. This promotes documents that rank well in both approaches.
Stage 2: Precision Reranking
Apply cross-encoder models to the top 50-100 candidates for deep query-document comparison, yielding the final 3-5 most relevant chunks for generation.
Trade-off: Reranking adds latency but significantly improves relevance quality.
Step 3: Generation Pipeline
Convert retrieved context into coherent, grounded responses through controlled generation.
Context Integration Strategy
Augmented Prompting Template:
You are an expert analyst. Using ONLY the information provided below,
answer the user's question. If the context doesn't contain sufficient
information, state this clearly.
Context: {retrieved_chunks}
Question: {user_query}
Provide a clear, accurate response with citations to specific sources.
Generation Control: Use low temperature (0.1-0.3) for factual responses and implement systematic citation mechanisms linking generated content back to source documents.
Step 4: Evaluation and Quality Assurance
Retrieval Metrics
Hit Rate: Percentage of queries where relevant documents appear in results
Mean Reciprocal Rank (MRR): How quickly relevant documents appear in rankings
nDCG: Overall ranking quality considering both relevance and position
Generation Assessment
Faithfulness: How well responses adhere to retrieved context (use LLM-as-Judge scoring)
Answer Relevance: Whether responses directly address user queries
Human Review: Sample 5% of responses for high-stakes applications
Production Case Study: Financial Services Implementation
Challenge & Results
A major investment bank implemented RAG for regulatory filings and research reports access.
Before RAG:
- Query response time: Manual search taking significant time
- Information accuracy: Frequent outdated data issues
- Analyst productivity: Limited by time spent searching
After RAG:
- Query response time: Near real-time responses
- Information accuracy: Substantial improvement with proper citations
- Analyst productivity: Significant increase in research output
- Hallucination rate: Dramatic reduction through grounded responses
Key Success Factors: Domain-specific evaluation, human-in-the-loop review, iterative improvement based on user feedback
Step 5: Production Implementation
RAG Architecture Decision Framework
Simple Q&A (FAQ, docs) → Basic Vector Search
├─ < 100K docs: Single-node vector DB
└─ > 100K docs: Distributed vector DB
Complex Research/Analysis → Hybrid Search + Reranking
├─ Latency critical: Cache-optimized architecture
└─ Accuracy critical: Multi-stage reranking pipeline
Multi-step Reasoning → Agentic RAG
├─ Budget < $10K/month: Simplified ReAct
└─ Budget > $10K/month: Full multi-agent orchestration
Key Decision Point: Reranking adds latency but substantially improves relevance quality
Production Troubleshooting Guide
High Retrieval Latency:
- Implement result caching (significantly reduces repeated queries)
- Optimize vector DB configuration (sharding, replica placement)
- Use smaller reranking models or reduce candidate sets
Poor Context Quality:
- Check hit rate metrics to identify retrieval issues
- Adjust chunk size/overlap strategies
- Add metadata filtering (date, document type, author)
- Implement domain-specific embedding fine-tuning
High Embedding Costs:
- Use batch processing for substantial cost reduction
- Implement incremental updates (only new/changed content)
- Apply document deduplication before embedding
- Consider open-source embedding alternatives
Response Hallucination:
- Lower temperature for more factual generation
- Strengthen prompt constraints (“only use provided context”)
- Implement faithfulness scoring for automatic detection
- Add confidence scoring and uncertainty expressions
Enterprise Integration Patterns
Existing Search Integration: Layer RAG on top of current Elasticsearch infrastructure using hybrid search approaches
CI/CD Integration: Implement automated pipelines for knowledge base updates with validation steps
Monitoring Integration: Track retrieval latency, context quality scores, and query patterns with alerting on quality degradation
Step 6: Performance Optimization and Trade-offs
Architecture Performance Characteristics
| Architecture | Retrieval Speed | End-to-End Response | Query Throughput | Complexity |
|---|---|---|---|---|
| Basic Vector Search | Fast | Quick | High | Low |
| Hybrid + Reranking | Moderate | Moderate | Medium | Medium |
| Agentic RAG | Slow | Extended | Low | High |
Quality vs Cost Considerations
Embedding Model Selection:
- Proprietary APIs: Higher quality, easier setup, ongoing costs
- Open-source alternatives: Lower costs, more control, additional infrastructure
- Domain-specific fine-tuned: Best quality for specialized use cases, highest complexity
Reranking Trade-offs:
- Without reranking: Faster responses, lower quality results
- With cross-encoder reranking: Better relevance, increased latency and costs
Advanced RAG Patterns
Agentic RAG with ReAct
Combine retrieval with multi-step reasoning:
- Reason: “User needs recent financial data, search SEC filings”
- Act: Search knowledge base for relevant documents
- Observe: Retrieved financial document sections
- Reason: “Verify calculation methodology”
- Final Answer: Synthesized response with citations
Hybrid Architecture Integration
RAG + Fine-Tuning: Combine retrieval capabilities with domain-specific model behavior for optimal performance
Multi-Modal RAG: Extend beyond text to include document layout, tables, and structured data processing
Common Failure Modes and Solutions
No Relevant Context: Implement graceful fallbacks with uncertainty statements
Poor Context Quality: Use reranking models and context quality scoring
Hallucination Despite Context: Strengthen prompt constraints and implement faithfulness monitoring
Scalability Issues: Implement distributed architecture with proper caching strategies
What’s Next
RAG provides the foundation for connecting LLMs to dynamic information sources, but the full potential is realized when combined with specialized model behavior. In our final post, we’ll explore Fine-Tuning—how to modify model parameters to create domain experts that work seamlessly with RAG architectures.
Follow along as we complete the LLM customization trilogy with advanced fine-tuning techniques, parameter-efficient methods, and strategies for building truly specialized AI systems!
:%20Building%20Production%20RAG%20Systems){kind=link}