A Practical Guide for LLM Customization (Part 4): Fine-Tuning for Specialized AI Systems
A Practical Guide for LLM Customization (Part 4): Fine-Tuning for Specialized AI Systems
In our previous posts, we explored prompt engineering for behavior control and RAG for knowledge access. Today, we complete the trilogy with Fine-Tuning—modifying model parameters to create truly specialized AI systems.
Fine-tuning transforms general-purpose models into domain experts with consistent behavior, specialized reasoning, and reliable output formatting. This guide covers the complete process from strategic decisions through production deployment.
Why Fine-Tune?
Fine-tuning solves problems that prompt engineering and RAG cannot:
Behavioral Consistency: Embeds reliable patterns directly into model weights, eliminating complex prompt management.
Specialized Reasoning: Integrates domain expertise at the parameter level for natural, specialized logic.
Format Reliability: Ensures deterministic structured outputs (JSON, SQL, XML) without prompt engineering.
Privacy Control: Enables on-premise deployment with complete data governance.
Cost Efficiency: Reduces inference costs and latency by eliminating retrieval overhead and complex prompts.
Key Insight: Fine-tuning changes how a model thinks, while RAG provides what it knows.
The Fine-Tuning Process
Fine-tuning follows five sequential phases:
- Model Selection: Choose base model considering capabilities, licensing, and infrastructure
- Data Preparation: Curate high-quality training datasets with validation and splitting
- Training: Execute parameter-efficient fine-tuning with monitoring
- Evaluation: Benchmark against baselines with automated and human assessment
- Deployment: Production serving with monitoring and continuous improvement
Critical Factor: Quality data preparation determines success more than training optimization.
Step 1: Model Selection and Architecture
Your base model choice impacts training costs, deployment complexity, and capabilities.
Base Model Options
Open-Source Models:
- Llama 2/3: Strong capabilities, commercial licensing
- Mistral: Efficient architecture, excellent performance-to-size ratio
- Specialized variants: CodeLlama, domain-specific models
- Benefits: Complete control, privacy, predictable costs
- Costs: Infrastructure complexity, management overhead
Proprietary APIs:
- OpenAI GPT-4: High quality, simple integration
- Claude: Strong reasoning, safety-focused
- Gemini: Google ecosystem integration
- Benefits: Minimal infrastructure, regular improvements
- Costs: Limited customization, ongoing API fees, vendor dependency
Parameter-Efficient Methods
Modern techniques dramatically reduce resource requirements:
LoRA (Low-Rank Adaptation): Adds trainable matrices to frozen layers, reducing parameters by 90%+ while maintaining performance.
QLoRA: Combines LoRA with 4-bit quantization, enabling large model fine-tuning on consumer hardware.
Adapters: Insert trainable modules between layers for multiple specialized behaviors.
Step 2: Data Strategy and Curation
Success depends on data quality—fine-tuning amplifies all patterns in training data.
Quality-First Approach
Scale Guidelines:
- prompt, response pairs format
- Simple tasks: 100-500 high-quality examples
- Complex reasoning: 1,000-10,000 examples
- Rule: 500 curated examples > 5,000 inconsistent ones
Collection Strategies:
- Expert-generated: Highest quality, domain accuracy
- Synthetic: Scalable using strong models, requires validation
- Production samples: Real-world relevance with filtering
Data Standards
Quality Validation:
- Consistency: Uniform response patterns
- Accuracy: Expert technical review
- Coverage: Full scope representation
- Bias check: Remove harmful content
Data Splitting: 70-80% training, 10-15% validation, 10-15% test with stratified sampling.
Step 3: Training Infrastructure and Process
Choose infrastructure balancing convenience, cost, and control.
Infrastructure Options
Managed Platforms (AWS SageMaker, Google AI, Azure ML):
- Pros: Automatic scaling, integrated tools, minimal setup
- Cons: Ongoing costs, platform lock-in
Self-Managed (on-premise/cloud instances):
- Pros: Cost control, data security, full customization
- Cons: Infrastructure management, technical expertise required
Training Configuration
Key Hyperparameters:
- Learning rate: 1e-5 to 1e-4 (start conservatively) with cosine scheduling
- Batch size: Balance memory and stability
- LoRA rank: Higher rank = more capacity + memory
Essential Monitoring:
- Loss curves: Track training/validation convergence
- Early stopping: Prevent overfitting automatically
- Checkpoints: Regular snapshots for recovery
Step 4: Evaluation and Quality Assurance
Comprehensive evaluation ensures production readiness and validates your investment.
Evaluation Framework
Automated Metrics:
- Classification: Accuracy, precision, recall, F1-score
- Generation: BLEU, ROUGE, semantic similarity
- Structure: Format compliance, schema validation
Human Assessment:
- Expert review: Domain specialist evaluation
- A/B testing: Blind comparison against baselines
- Production sampling: Real-world quality assessment
Benchmarking
Baseline Comparisons:
- Base model: Measure improvement over foundation model
- Prompt engineering: Compare against optimized prompts
- RAG systems: Evaluate retrieval-augmented alternatives
Regression Testing:
- General capabilities: Ensure no degradation of broad skills
- Edge cases: Test unusual inputs and adversarial examples
- Bias evaluation: Systematic harmful output detection
Step 5: Production Deployment and Management
Deploy with infrastructure for monitoring, versioning, and continuous improvement.
Deployment Architecture
Serving Options:
- Dedicated servers: Maximum control, custom optimization
- Managed platforms: Auto-scaling, integrated monitoring
- Edge deployment: Low latency, offline capability
Version Management:
- Model registry: Centralized versioning and storage
- A/B testing: Gradual rollout with performance comparison
- Rollback capability: Quick reversion when issues arise
Production Operations
Performance Monitoring:
- Quality metrics: Automated response scoring
- System metrics: Latency, throughput, resource usage
- Error tracking: Failure modes and edge case handling
Continuous Improvement:
- Drift detection: Monitor input/output distribution changes
- Performance alerts: Automatic notifications on quality drops
- Feedback loops: Integrate production data into future training
Maintenance Cycles:
- Regular evaluation: Systematic performance assessment
- Incremental updates: Periodic fine-tuning with new data
- Model lifecycle: Planned deprecation and replacement
Advanced Patterns and Integration
Hybrid Architectures
Fine-Tuning + RAG: Combine specialized reasoning with current knowledge access for optimal performance.
Multi-Model Systems: Deploy different fine-tuned models for specific tasks with intelligent routing.
RLHF and Beyond
Human Feedback Training: Align outputs with user preferences through reinforcement learning.
Constitutional AI: Train models to follow principles through self-supervised learning.
Common Pitfalls and Solutions
Data Issues:
- Problem: Poor quality or biased training data
- Solution: Systematic curation, expert validation, bias detection
Training Problems:
- Overfitting: Model memorizes training data
- Solution: Early stopping, validation monitoring, regularization
Production Challenges:
- Model drift: Performance degrades over time
- Solution: Continuous monitoring, automated retraining triggers
Implementation Decision Matrix Between SaaS Fine-Tuning vs. Open-Source
| Factor | SaaS Fine-Tuning | Open-Source |
|---|---|---|
| Time to Deploy | Days | Weeks |
| Technical Expertise | Minimal | High |
| Data Privacy | Limited | Complete |
| Customization | Constrained | Full |
| Best For | Quick prototypes | Specialized needs |
The Complete LLM Customization Stack
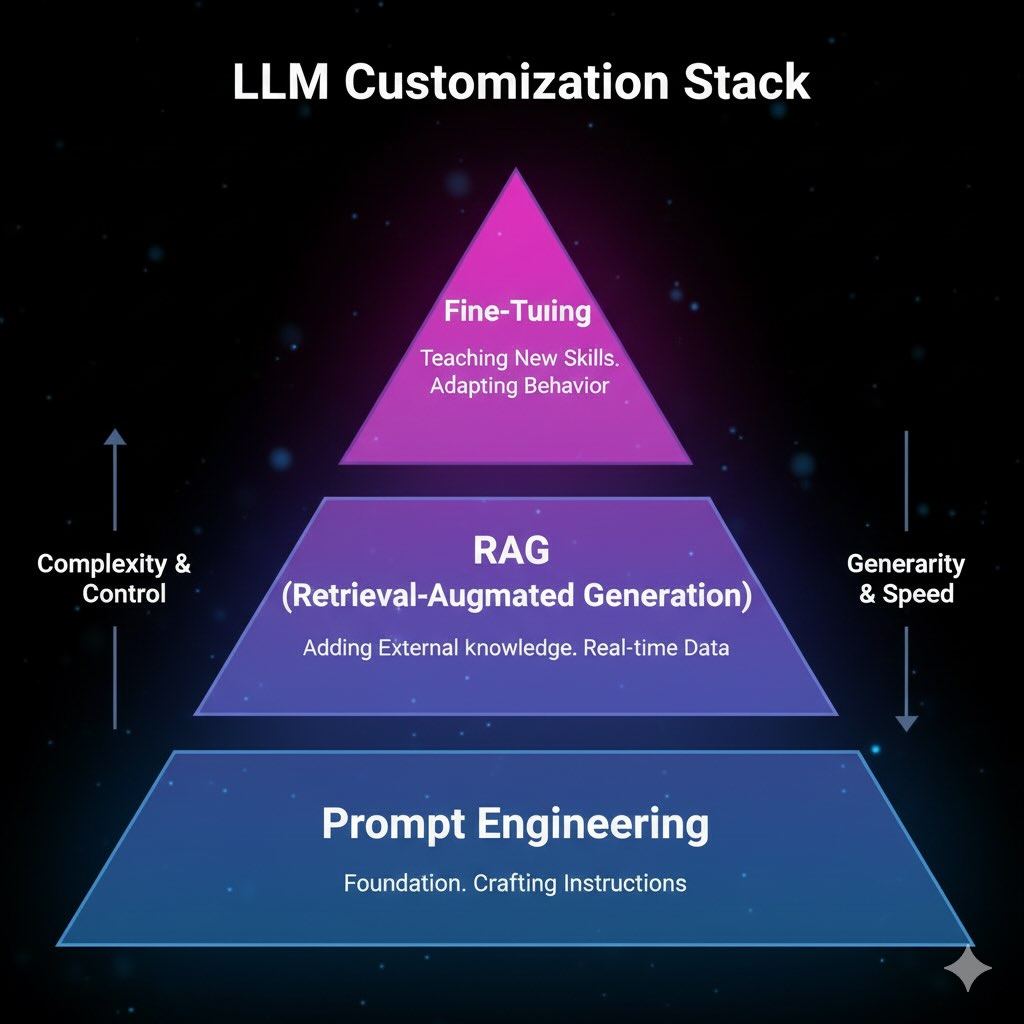
Integration Strategy
Layered Approach:
- Foundation: Choose appropriate base model
- Fine-Tuning: Embed domain expertise and behavioral patterns
- RAG Layer: Add current, factual information access
- Prompt Engineering: Fine-tune specific interactions
Synergistic Benefits:
- Specialized reasoning + current knowledge = expert systems with up-to-date information
- Consistent behavior + dynamic content = reliable yet adaptive AI
- Domain expertise + factual grounding = trustworthy specialized intelligence
Implementation Phases
Phase 1: Start with prompt engineering for rapid iteration
Phase 2: Add RAG for knowledge access and grounding
Phase 3: Implement fine-tuning for consistency and specialization
Phase 4: Optimize integrated system for production performance
Conclusion
Fine-tuning completes our comprehensive exploration of LLM customization. By strategically combining prompt engineering, RAG, and fine-tuning, you can build AI systems that are both capable and truly specialized for your requirements.
The future lies in intelligent orchestration of these techniques, creating systems that blend consistent behavior, current knowledge, and specialized expertise. Organizations mastering this integration will build the most valuable and competitive AI applications.
Start with your most pressing need, but plan for the integrated approach that delivers your AI system’s full potential.
:%20Fine-Tuning%20for%20Specialized%20AI%20Systems){kind=link}